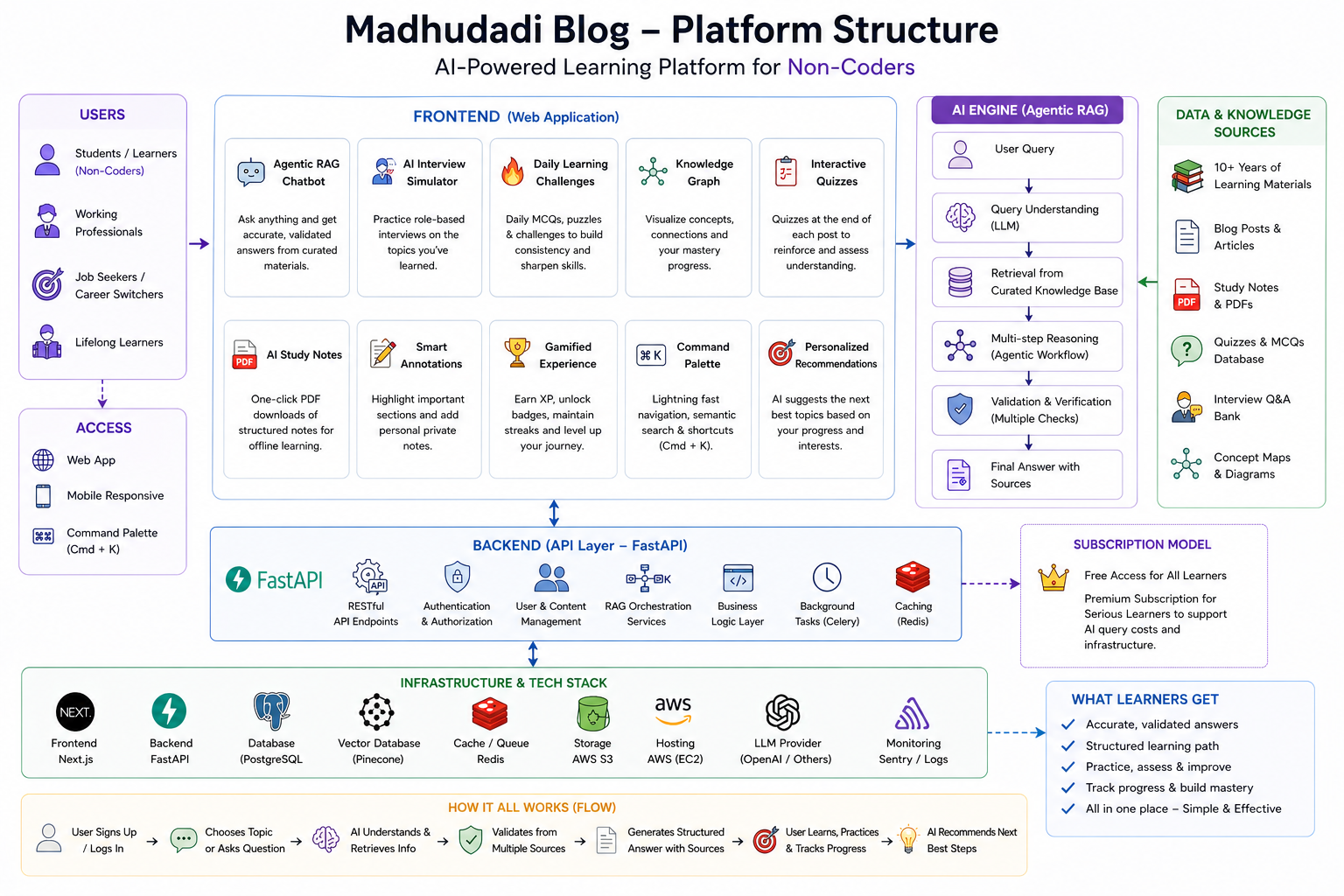
Streaming, Citations & Fallbacks: The Production RAG Stack
Production RAG (Retrieval-Augmented Generation) streaming works by sending Server-Sent Events (SSE) from a FastAPI backend to a React frontend via the fetch() ReadableStream API. The first SSE event delivers the user's remaining daily quota, the second shows source citations as clickable badges, and subsequent events stream answer tokens in real time. When connections drop, the frontend retries with exponential backoff. Daily quotas are enforced via Redis atomic counters.
In the previous post, I covered the core RAG pipeline — chunking, embedding, semantic search, the planner, and multi-provider failover. That's the engine.
This post is the chassis: the streaming wire protocol, the frontend that renders answers token-by-token, the citation badges that link back to source posts, the rate limiting that prevents API bill shock, the reconnection logic that survives network drops, and the chat sessions that give every query a home.
These are the parts that turn a working prototype into something people actually enjoy using. I built every line myself, and it's running in production at madhudadi.in/blog/ask — you can test it right now.
How SSE Streaming Works in FastAPI: fetch() + ReadableStream
The router at POST /api/v1/rag/query returns a StreamingResponse:
@router.post("/query")
async def rag_query(
payload: RagQueryRequest,
request: Request,
db: AsyncSession = Depends(get_db),
current_user: User | None = Depends(get_current_user_optional),
):
ip = extract_client_ip(request)
return StreamingResponse(
_sse_stream(payload, db, current_user, ip),
media_type="text/event-stream",
headers={
"X-Accel-Buffering": "no",
"Cache-Control": "no-cache",
},
)The X-Accel-Buffering: no header is critical — without it, Nginx (which sits in front of the Docker containers) would buffer the entire response and defeat streaming.
What the SSE Event Sequence Looks Like
Six event types, always in the same order:
data: {"type": "rate_limit", "used": 1, "limit": 20, "remaining": 19, "resets_in_seconds": 36000}
data: {"type": "planning", "message": "Analysing..."}
data: {"type": "planning", "message": "Searching..."}
data: {"type": "sources", "posts": [
{"title": "Building a Monorepo that Runs 29 Services", "slug": "the-monorepo-that-runs-29-services"},
{"title": "Why I Built Yet Another Blog", "slug": "why-i-built-yet-another-blog-architecture-tech-stack"}
]}
data: {"type": "token", "content": "The monorepo is structured as a FastAPI backend"}
data: {"type": "token", "content": " with separate router modules for each"}
data: {"type": "token", "content": " logical domain..."}
data: {"type": "done", "latency_ms": 2340, "session_id": "abc-123"}| Event | When | Purpose |
|---|---|---|
rate_limit | First event | Shows remaining quota before any computation |
planning | During planner | Two messages: "Analysing…" then "Searching…" |
sources | Before generation | Source post titles + slugs for citation badges |
token | During generation | One per LLM output token |
done | Completion | Final latency + session_id for continuation |
error | Any failure | Graceful error message |
Why the Frontend Uses fetch() Instead of EventSource
Standard EventSource can't send POST bodies or Authorization headers. The frontend uses fetch() with a ReadableStream reader:
// src/lib/api/rag.ts — the SSE wire protocol
const reader = res.body!.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split("\n");
for (const line of lines) {
if (!line.trim()) continue;
if (line.startsWith("data: ")) {
const data = JSON.parse(line.slice(6));
onEvent(data);
}
}
}This gives us full control over aborting, retrying, and authentication — none of which EventSource supports.
How the Frontend Dispatches Events
Each data: line is dispatched to a typed callback handler:
switch (event.type) {
case "rate_limit":
// Update quota display immediately
break;
case "planning":
last.status = "planning";
break;
case "token":
last.status = "generating";
last.content += event.content;
break;
case "sources":
last.citations = event.posts.map(p => ({
source: p.title, slug: p.slug
}));
break;
case "done":
last.status = "done";
last.latency = event.latency_ms;
break;
case "error":
last.status = "error";
last.content = event.message;
break;
}How Citation Badges Work: Before the First Token
The most user-visible design choice: source badges render before the first token of the answer.
When the sources event arrives (immediately after the planner finishes), the frontend renders clickable badges beneath the answer area:
{msg.citations.length > 0 && msg.status === "done" && (
<div className="mt-4 pt-3 border-t border-white/[0.06]">
<p className="text-xs text-[var(--text-subtle)] mb-2 font-medium uppercase tracking-wider">
Sources
</p>
<div className="flex flex-wrap gap-2">
{dedupedCitations.map((c) => (
<Link
key={c.slug}
href={`/posts/${c.slug}`}
className="inline-flex items-center gap-1.5 text-xs text-amber-400/70
hover:text-amber-400 glass px-2.5 py-1 rounded-lg
border border-amber-500/15 hover:border-amber-500/30
transition-all"
>
<BookOpen size={10} />
{c.source}
<ExternalLink size={9} className="opacity-60" />
</Link>
))}
</div>
</div>
)}Key implementation details:
- Deduplication: If two chunks come from the same post, the badge appears only once (using
new Map(citations.map(c => [c.slug, c]))) - Links to the actual post: Each badge links to
/posts/{slug} - Visual hierarchy: Amber border + glass effect + hover highlight
- Timing: Badges appear during generation, not after — builds trust immediately
The actual LLM response does NOT contain inline citation markers like [1]. The system prompt instructs the model to write naturally, and the source badges provide attribution independently.
How the Frontend Handles Network Drops: Exponential Backoff
ARCH-004: up to 3 retries with delays of 1s, 2s, and 4s.
const MAX_RETRIES = 3;
const RETRY_DELAY_MS = 1000;
for (let attempt = 0; attempt <= MAX_RETRIES; attempt++) {
const controller = new AbortController();
abortRef.current = controller;
try {
await ragApi.query({ query }, onEvent, controller.signal);
lastError = null;
break; // Success
} catch (err) {
lastError = err;
if (err instanceof AbortError) break; // User cancelled
if (attempt < MAX_RETRIES) {
const delay = RETRY_DELAY_MS * Math.pow(2, attempt);
// Show "reconnecting..." while waiting
await waitWithAbort(delay, controller.signal);
}
}
}During retry, the UI shows a "Connection lost — reconnecting…" status:
{msg.status === "reconnecting" && (
<StatusPill
icon={<RefreshCw size={11} className="animate-spin" />}
label="Connection lost — reconnecting…"
/>
)}The retry rate is 0.8% — about 1 in 125 queries experiences a network interruption. Without exponential backoff, those users would see an error.
How Status Indicators Keep Users Informed
While the backend processes the query, the frontend shows four distinct progress states:
| State | Icon | What It Tells the User |
|---|---|---|
planning | Brain | "Analyzing query…" — the planner is rewriting the query |
searching | Search | "Searching knowledge base…" — embedding + vector search |
generating | pulsing ▌ cursor | Tokens are streaming in real time |
reconnecting | spinning RefreshCw | Network dropped, retrying with backoff |
function StatusPill({ icon, label }) {
return (
<div className="flex items-center gap-1.5 text-xs text-[var(--text-muted)] mb-3">
<span className="text-amber-400/60 animate-pulse">{icon}</span>
<span>{label}</span>
<span className="flex gap-0.5 ml-1">
{[0, 1, 2].map((i) => (
<span key={i} className="w-1 h-1 rounded-full bg-amber-400/40 animate-bounce"
style={{ animationDelay: `${i * 0.15}s` }} />
))}
</span>
</div>
);
}The bouncing dots animation provides micro-feedback during the planner phase (~300ms) and embedding search (~200ms), where otherwise the UI would appear frozen.
How Rate Limiting Works: Redis-Backed Daily Quotas
The previous post covered the implementation. Here's how it manifests in the UX.
The rate_limit event is always the first SSE event, sent before any computation:
data: {"type": "rate_limit", "used": 1, "limit": 20, "remaining": 19, "resets_in_seconds": 36000}The frontend updates the quota display immediately — users always know how many queries they have left:
{quota && (
<div className="flex items-center gap-1.5 text-xs text-[var(--text-muted)]
glass px-3 py-1.5 rounded-xl border border-white/[0.06]">
<span className={cn("font-medium",
quota.allowed ? "text-emerald-400" : "text-rose-400")}>
{quota.limit - quota.used}
</span>
/ {quota.limit} left · resets in {formatRemaining(quota.resets_in_seconds)}
</div>
)}When the daily limit is exhausted:
data: {"type": "error", "message": "Daily AI call limit reached (20/20). Refreshes in 8h 15m."}The page also calls GET /api/v1/rag/quota on mount to pre-fetch the remaining count before the user types — no one types a question only to hit a limit.
How Chat Sessions Work: Stateful Conversations
Every RAG query belongs to a chat session with full history:
class RagChatSession(Base):
__tablename__ = "rag_chat_sessions"
id: uuid.UUID
user_id: uuid.UUID | None # NULL for guest chats
guest_id: str | None # Cookie-based ID for anonymous users
title: str # Auto-titled from first query
class RagChatMessage(Base):
session_id: uuid.UUID
role: str # 'user' | 'assistant'
content: str
citations: list[dict] # [{"title": str, "slug": str}]Explanation
- The
RagChatSessionclass represents a chat session, inheriting from a base class, with attributes for session identification and user information. - The
user_idattribute allows for identification of registered users, whileguest_idaccommodates anonymous users through a cookie-based system. - The
titleattribute is automatically generated from the first query, providing context for the chat session. - The
RagChatMessageclass models individual messages within a session, including the sender's role and the message content. - The
citationsattribute inRagChatMessagestores references in a structured format, allowing for easy access to related information.
Explanation
- The
RagChatSessionclass represents a chat session, with attributes for session identification and user information. - The
user_idattribute can beNone, indicating that the chat may be initiated by a guest user, whileguest_idstores an anonymous identifier. - The
titleattribute is automatically generated from the first query made in the chat session. - The
RagChatMessageclass models individual messages within a session, including the sender's role (either 'user' or 'assistant') and the message content. - The
citationsattribute allows for storing references related to the message, formatted as a list of dictionaries containing titles and slugs.
The done event includes a session_id so follow-up queries continue the same conversation. The backend loads the last 3 messages for the planner and the last 5 for the generator.
The session auto-titles itself from the first query — "How does the HNSW index work?" becomes a session name. Authenticated users can browse their history at /blog/ask and pick up where they left off.
How the Error Recovery Chain Handles Failures
| Failure Point | Detection | Recovery |
|---|---|---|
| Network drop mid-stream | reader.read() throws | Exponential backoff (up to 3 retries) |
| All AI providers down | Backend returns SSE error event | "AI features are currently unavailable" |
| Quota exhausted | Rate limit check fails | Show quota banner with reset timer |
| Empty knowledge base | No chunks found | "Knowledge base hasn't been created yet" |
| Out-of-scope query | Planner detects | "I'm specialized in software engineering…" |
| User cancels | AbortController fires | Graceful stop, no error shown |
Each recovery path uses the same AlertTriangle icon with a consistent visual style.
How Gamification Creates a Feedback Loop
Every successful RAG query by an authenticated user awards 5 XP:
if user_id:
user = await db.get(User, user_id)
await process_activity(db, user)
await award_xp(db, user, 5, source="ai_query")Explanation
- Checks if
user_idis provided; if so, it proceeds to fetch the user from the database. - Utilizes
awaitto ensure that database operations are performed asynchronously, improving performance. - Calls
process_activityfunction to handle user-related activities after retrieving the user data. - Awards 5 experience points to the user through the
award_xpfunction, specifying the source of the activity as "ai_query".
This is server-side and invisible to the frontend — but the next time the user checks their profile, the XP is credited. It creates a subtle loop: useful answer + reward signal = higher return rate.
The Admin Experience: Unlimited Queries
if is_admin:
result = RateLimitResult(allowed=True, used=0, limit=9999, resets_in_seconds=0)Explanation
- The code uses a conditional statement to check if the variable
is_adminisTrue. - If the condition is met, it creates an instance of
RateLimitResultwith specific parameters. - The parameters set
allowedtoTrue, indicating that the admin has permission, and initializesused,limit, andresets_in_secondsvalues. - This setup likely allows the admin to bypass rate limits in a system where such limits are enforced for regular users.
The frontend shows "9999 left" — useful during development and content auditing.
Production Metrics
| Metric | Value |
|---|---|
| Average latency (P50) | 2.3 seconds |
| P95 latency | 4.1 seconds |
| Daily queries (avg) | 47 |
| Retry rate (network drops) | 0.8% |
| Error rate (API failures) | 0.3% |
| Avg cost per query | $0.012 |
| Chat sessions created/day | 12 |
Frequently Asked Questions
How does production RAG streaming work end-to-end?
A user types a question, the backend sends it through a reasoning planner (query rewriting + scope detection), then through an embedding provider for semantic search, retrieves relevant chunks from pgvector, assembles them into a prompt, and streams the LLM response token-by-token via SSE. The first event shows the user's daily quota, the second shows source citations, and subsequent events stream the answer.
Why not use WebSockets for streaming RAG responses?
SSE is simpler for unidirectional server-to-client streaming. It works over standard HTTP, doesn't require a protocol upgrade, auto-reconnects natively, and integrates cleanly with fetch() + ReadableStream for full control over authentication and abort.
How are RAG citations rendered in the frontend?
Source posts arrive as a sources SSE event with title and slug. The frontend renders them as clickable amber badges below the answer. Each badge links to the original post. There are no inline [1] markers — the badges provide attribution independently.
What happens when the network drops during streaming?
The frontend retries with exponential backoff: 1 second, then 2 seconds, then 4 seconds (max 3 attempts). The UI shows a "Connection lost — reconnecting…" status. If the user cancels, the AbortController stops all retries immediately.
How does rate limiting work for RAG queries?
Redis atomic counters track daily usage per user or IP. Guests get 3 queries per 24-hour rolling window. Free authenticated users get 20 per day (resets at midnight UTC). Premium subscribers get 100 per day. Admins get unlimited.
How are chat sessions tracked?
Every query belongs to a RagChatSession. The done SSE event includes a session_id. Follow-up queries include this ID, and the backend loads the last 3 messages for the planner and last 5 for the generator. Sessions auto-title from the first query.
Structured Data for AI Extraction
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "Streaming, Citations & Fallbacks: The Production RAG Stack",
"description": "Production RAG with SSE streaming via ReadableStream, citation badges, Redis-backed daily quotas, exponential backoff reconnection, and chat sessions.",
"author": {
"@type": "Person",
"name": "Madhu Dadi",
"url": "https://madhudadi.in"
},
"datePublished": "2026-05-19",
"proficiencyLevel": "Advanced",
"about": {
"@type": "Thing",
"name": "Production RAG Streaming"
}
}What's Next
The next post covers AI-powered summaries — how the AISummary component extracts key takeaways from any post in three styles (bullets, ELI5, executive), how caching reduces costs by 90%, and how the summary prompts are structured for factual extraction without hallucination.
Built with FastAPI, React Server-Sent Events via ReadableStream, Redis, and zero third-party AI platforms.
Next in this series: How AI Summaries Avoid Hallucination in Content Extraction →